[请勿转载]
什么是微服务架构
在上一章中,我们认识了什么是单块架构应用,并分析了随着互联网时代的快速发展,随着市场变化快,用户需求变化快以及用户访问量的增加,单块架构应用的维护成本、人员的培养成本、缺陷修复成本以及技术架构演进的成本和系统扩展成本等都在增加,因此单块架构曾经的优势已逐渐无法适应互联网时代的快速变化,面临着越来越多的挑战。
在本章中,我们来了解到底什么是微服务架构,以及为什么微服务架构能有效解决单块架构在互联网时代所面临的挑战。
概述
微服务架构一词在过去几年里,得到了广泛的讨论和关注。微服务架构提倡通过对特定业务领域的分析与建模,将复杂的、 集中的、耦合度高的应用系统分解成小而专、耦合度低并且高度自治的一组服务。这些服务与服务之间相互协作、相互配合,从而为最终用户或其他系统提供相应的功能。微服务将每个独立的业务逻辑划分出来,运行在它们自己的进程中,然后通过分布式的网络互相通信与协作,从而为终端用户或其他调用者提供灵活的接口。
与传统IT行业的'服务架构'概念不一样的是,微服务更强调的是一种独立测试、独立部署、独立运行的软件架构模式。微服 务中的每个服务,都可以作为一个独立的业务单元进行测试、部署,而且每个服务都能独立运行在不同的进程中。这些微服务满足细粒度的业务需求,并使用自动化部署工具进行发布。同时,这些微服务可以使用不同的开发语言,不同框架,以及不同的数据存储技术,因此相比与'服务架构',它是一种高度自治的、非集中式管理的、细粒度的业务单元。
实际上,微服务架构并不是一个全新的概念。早在二十几年前,面向服务架构(SOA)概念的提出,就已经阐述了类似的思 想,“对于复杂的企业IT系统,应按照不同的、可重用的粒度划分,将功能相关的一组提供者组织在一起为消费者提供服务”。 仔细分析SOA的概念,就会发现,其在服务的定义上和我们今天所谈到的微服务定义大致类似,那为什么在SOA的概念提出这么多年后,又诞生了这个貌似是新瓶装旧酒的微服务架构呢?其实,鉴于过去十几年互联网行业的高速发展,以及敏捷、持续集成、持续交付、DevOPS,云技术等的深入人心,服务架构的开发、测试、部署以及监控等,相比我们提到的传统的SOA,已经大相径庭。相比SOA,微服务要更具有独立性、灵活性、可实施性以及可扩展性。换句话说,微服务架构可以被认为是一种更接地气的面向服务架构,是一种更容易帮助企业或组织构建演进式架构的方法和实践。关于更多SOA与微服务的区别,请参考[X部分]。
微服务架构的定义
其实,即便了解了上面的介绍,还是很难对微服务下一个准确的定义。就像NoSQL,我们谈论了好几年的NoSQL,知道NoSQ L代表着什么样的含义,也可以根据不同的应用场景选择不同的NoSQL数据库,但是我们还是很难对它下一个准确的定义。类似的,关于什么是‘函数式编程’,也或多或少存在同样的窘境。我们可以轻松的选择不同的函数式编程语言,可以轻松的写出函数式编程风格的代码,但很难对什么是函数式编程下一个准确的定义。
实际上,从业界的讨论来看, 微服务本身并没有一个严格的定义。不过,ThoughtWorks的首席科学家,马丁- 福勒先生对微服务的这段描述,似乎更加具体、贴切,通俗易懂:
The microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值 。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通(通常是基于HTTP协议的RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。另外,应当尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建。
如果我们仔细分析这段话,不难发现,对于微服务的定义,我们可以从以下几个方面考虑:
小,且专注于做一件事情
微服务架构通过对特定业务领域的分析与建模,将复杂的应用分解成小而专一、耦合度低并且高度自治的一组服务。每个服务都 是很小的应用。那么,微服务中提到的‘微’或者‘小’,到底是多‘微’、多‘小’呢?

实际上,关于多小的服务才合适,是一个非常有趣的话题。有人觉得使用代码行数来作为‘微’的衡量标准比较合适,而有些人认为,既然是微服务,就应该简单。就应该在很短的时间内,譬如2周内,能够非常容易的重写该服务,这样才符合小和微的概念。
关于代码行数,我们知道,不同的语言有不同的特点。静态类型语言的主要优点在于其结构非常规范,存在编译期的语法检查、便于调试,类型安全性高,通常其继承关系简洁明了,IDE对其支持也更加友好;但缺点是为此需要写更多的类型相关代码。因此如果实现同样的功能,代码量相对稍多,这类语言的典型代表有Java、C#等;动态语言,其灵活性较高,运行时可以改变内存的结构,无类型检查,不需要写非常多的类型相关的代码;缺点自然就是不方便调试,命名不规范时会造成不易理解等,典型的代表如JavaScript、Ruby或者Python等。另外,还有一些数学类计算语言,能够使用非常简洁的公式实现其逻辑。
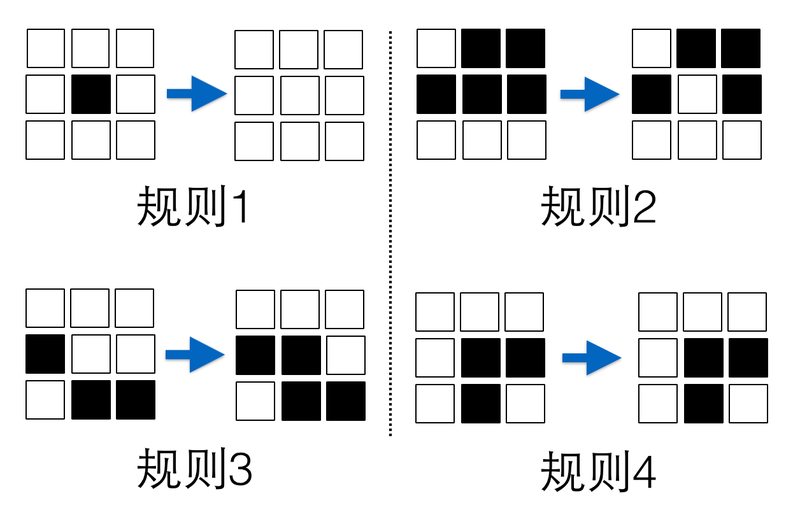
譬如说,对于经典的康威生命游戏而言,游戏开始时,细胞随机的被指定为存活或者死亡状态(黑色表示存活,白色表示死亡),每个细胞都会不断的演进,并且在演进的过程中,每个细胞下一代的状态由该细胞当前周围8个细胞的状态所决定,
其具体的规则如下图所示:
规则1,如果一个细胞周围有少于2个存活细胞,则该细胞无论存活或者死亡,下一代将死亡;
规则2,如果一个细胞周围有多于3个存活细胞,则该细胞无论存活或者死亡,下一代将死亡;
规则3,如果一个细胞周围有3个存活细胞,则该细胞下一代将存活;
规则4,如果一个细胞周围且仅有2个存活细胞,则该细胞下一代状态保持不变;
对于这个问题,各位如果感兴趣的话,可以尝试使用自己最擅长的语言来试试。
但这里,我想说的是,有一种语言叫APL(A Programing Language),如果我们使用它来实现,需要如下一行代码就可以解决该问题。
1
| |
因此,对于实现同样的功能,选择不同的语言,代码的行数会有千差万别。因此代码行数这种量化的数字显然无法成为衡量微服务是否够‘微’的决定因素。
另外,有些人认为,既然是微服务,就应该简单。譬如说,就应该在固定时间内(譬如2周),能够非常容易的重写,这样才符合微的概念。实际上,2周时间,对不同的个体而言 ,其服务重写的结果可能大相径庭。我们知道,对于重写这种情况,很大部分取决于个体的工作经验、擅长的语言、对业务背景的了解等等。譬如说,工作年限长的开发者通常情况下可能对其擅长的技术更熟练,而对业务熟悉程度较好的开发者,如果重写可能完成的更快。因此,多长时间能够重写该服务也不能作为衡量其是否小的重要因素。
因此,我个人认为,微服务的“微”并不是一个真正可衡量、看得见、摸得着的“微”。这个“微”所表达的,是一种设计思想和指导方针,是需要团队或者组织共同努力找到的一个平衡点。因此,微服务到底有多微,是个仁者见仁,智者见智的问题,最重要的是团队觉得合适就好。但注意,当考虑微服务的“微”时,至少应该遵循两个原则:业务独立性和团队自主性。首先,应该保证微服务是具有业务独立性的单元,在这个前提下,由团队来判断当前的服务大小是否合适,考虑到团队的沟通成本,一般不建议超过10个人,或者在超过10个人的团队中,可以再划分子团队。在这种情况下,当团队中大部分成员认为当前的服务是能够容易维护的、容易理解的,这就是我们认为适合团队的、有意义的“微”。
专注于做一件事情。从我们接触编程的第一天起,老师就教授我们,写出来的代码要符合“高内聚、低耦合”的原则,作为曾经似懂非懂的学生而言,我们也一直在朝 着这个方向努力着;另外,在面向对象设计的领域中,有几条放之四海而皆准的重要原则,那就是“SOLID原则”。大家请注意,在SOLID原则中的的第一条,叫单一职责原则(SRP-Single responsibility principle),其实描述的也是类似的事情。具体点说,单一职责原则的核心思想是:一个类,应该只有一个职责,也只有一个引起它变化的原因。如果一个类承担的职责过多,就等于把多个不同的职责耦合在了一起。这种耦合会导致当其中的某一职责发生变化时,可能会导致原本运行正常的其他职责或者功能发生故障。另外职责过多,也会导致引起该类变化的原因增多,多个职责之间相互依赖,容易产生影响,从而极大的损伤其内聚性和耦合度。Unix/Linux便是这一原则的完美体现者:在Unix中,各个程序都独立负责一个单一的事,我们可以通过管道将它们容易的连接起来。而Windows,则是这一原则的典型的反面示例:Windows中几乎所有的程序代码都交织耦合在一起,并没有做到一个类,只关注一个职责并把它做好。因此,如果希望避免这种现象的发生,就要尽可能的遵守单一职责原则,增强应用程序或者代码的内聚性以及降低耦合性。
运行在独立的进程中
在传统的单块架构应用中,我们通常将应用程序的代码分成逻辑上的三层、四层甚至更多层,但它并不是物理上的分层。这也 就意味着,经过开发团队对不同层的代码实现,经历过编译(如果非静态语言,可以跳过编译阶段)、打包、部署后,不考虑负载均衡以及水平扩展的情况,应用程序会运行在同一个机器的同一个进程中。
另外,为了提高代码的重用率以及可维护性,在应用开发中,我们有时也会将重复的代码提取出来,封装成组件。注意,这里所说的组件,指的是可以独立升级、独立替换掉的这一部分。在传统的单块架构中,组件通常的形态叫共享库,譬如JVM平台下的jar包、或者Windows下的DLL等,它们都是组件的一种形态。当应用程序在运行期时,所有的组件最终也会被加载到同一个进程中运行。如下图所示:
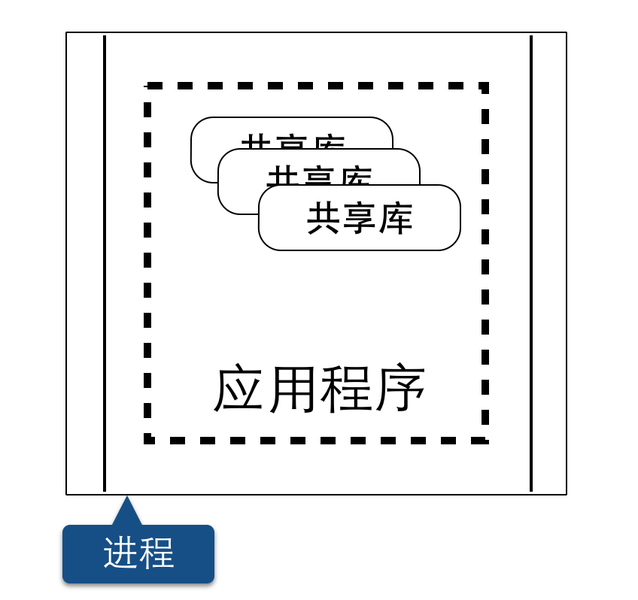
但在微服务的架构里,应用程序有多个服务组成,每个服务都是一个具有高度自治性的独立业务实体,通常情况下,每个服务都能够运行在一个独立的操作系统进程中,这就意味着不同的服务能非常容易的被部署到不同的主机上。
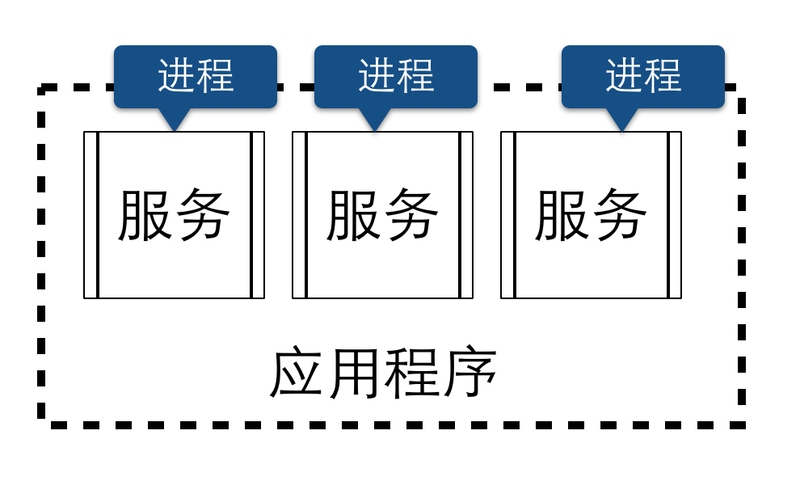
理论上,虽然我们能够将多个服务部署到同一台节点上,并让它们运行在不同的进程中,这种方式是可行的,但并不推荐这么做。作为微服务运行的环境,我们希望它能够保持高度的自治性和隔离性。如果多个服务运行在同一个服务器节点上,虽然省去了节点的开销,但是增加了部署和伸缩的复杂度。譬如,当部署某个新的服务时,如果当前节点正在运行的多个进程的多个服务,则必然会对这些服务造成影响。另一方面,如果运行在某个阶段的多个服务中,某些服务随着业务的发展需要伸缩,某些服务却不需要,如何有效的组织这些服务?会给服务的水平伸缩带来不必要的麻烦。
轻量级的通信机制
服务和服务之间通过轻量级的通信机制,实现彼此间的互通互联,互相协作。所谓轻量级通信机制,通常指基于语言无关、平 台无关、代码无关的这类协议,例如我们熟悉的XML或者JSON,他们的解析和使用与语言无关、平台无关。另外,基于HTTP协议,能让服务间的通信变得无状态化,目前大家所熟悉的REST(Representational State Transfer)就是服务之间互相协作常用的轻量级通信机制之一。 对于传统我们所熟知的Java RMI或者.Net Remoting等,虽然这类协议能够使用RPC的方式简化客户端的调用,使其像调用 本地接口一样调用远端的接口,但其最大的劣势在于,这类协议和语言、平台有非常强的耦合性,灵活性和扩展性较差。譬如说,如果使用了RMI作为通信协议,就意味着我们必须采用运行在JVM之上的语言才能完成互相协作。
对于微服务而言,通过使用语言无关、平台无关的轻量级通信机制,使服务与服务之间的协作变得更加简单、标准化。同时,服 务内部则可以选择任何语言、工具或者平台。
松耦合,独立部署
在传统的单块架构应用里,由于所有的功能都存在同一个代码库里。因此,当修改了该代码库的某个功能,在后续的测试过程中 都需要做回归测试,才能保证当前功能的修改不会影响其他已经工作的功能。也就是说,功能和功能之间存在着强耦合关系。
当测试完成后,通过持续集成或者其他机制,会构建新版本的部署包。这个大而全的部署包里,自然包括了应用的所有功能。当 将该部署包部署到生产环境或者类生产环境时,由于所有功能都运行在同一个进程中。因此,必须要停掉当前正在运行的进程,完成部署,然后再启动进程,相信这个部署的过程对大家都不陌生。
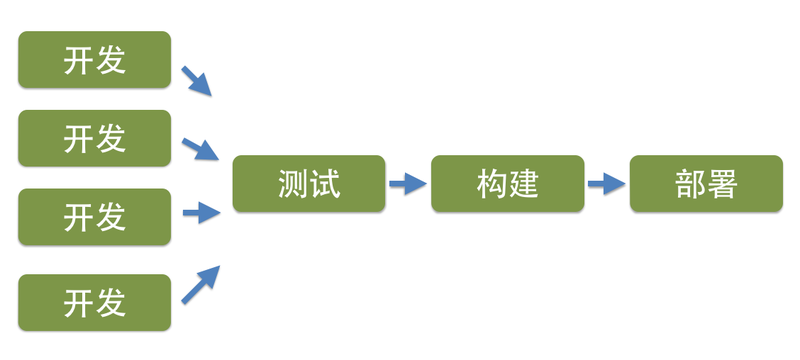
但是,如果当前应用程序里包含类似定时任务的功能,则要考虑什么时间窗口适合部署,是否需要先停掉原有的数据访问源,以 防止数据被读入应用程序内存,但未处理完而导致的数据不一致性。多年前,我曾经接触过一个JAVA项目,应用程序本身是个含有定时任务的系统,每隔5秒都会从数据库读入数据,然后将其转换成JMS的消息传给不同的内部组件。每次部署时候,我们都需要先关掉相关的消息队列,以防止数据被读入到应用,但还未被处理完,进程就被关闭而导致的数据不一致性。
微服务架构中,每个服务都是一个独立的业务单元,服务和服务之间是松耦合的。当对某个服务进行改变时,对其他的服务并不 会产生影响。
对于每个服务,最好能使用独立的代码库。这样的话,当我们对前服务的代码进行修改后,并不会影响其他服务。也就是说,从 代码库的层面,服务与服务是松耦合、高度解耦的。类似的,对于每个服务,都有独立的测试机制,因此,对当前服务代码的修改,也并不需要担心代码改动而导致的大范围的回归测试。因此,从测试的角度而言,服务和服务之间也是松耦合、高度解耦的。另外,由于构建包是独立的,部署流程也是独立的,服务的运行也是在不同的进程中。因此,从部署和运行的角度考虑,服务和服务之间同样是松耦合、高度解耦的。
因此,对于每个服务而言,与其他服务高度解耦,同时不需要改变其依赖,只改变当前服务本身,就可以完成部署。
总结
综上所述,微服务架构将一个复杂应用拆分成多个服务,服务与服务间能够互相协作、相互配合,从而为终端用户提供业务价值。每个服务独立运行在不同的进程中,服务与服务之间通过轻量的通讯机制交互,并且每个服务可以通过自动化部署方式独立部署。
微服务强调的是一种独立测试、独立部署、独立运行的软件架构模式。微服务中的每个服务,都可以作为一个独立的业务单元进行测试、部署,而且每个服务都能独立运行在不同的进程中。这些微服务满足细粒度的业务需求,并使用自动化部署工具进行发布。同时,这些微服务可以使用不同的开发语言,不同框架,以及不同的数据存储技术,因此它是一种高度自治的、非集中式管理的、细粒度的服务单元。